TRAG - 基于类型定义的检索增强生成
Abstract
TRAG 架构有效弥合了自然语言与结构化数据之间的鸿沟,使得 LLM 可以更轻松地集成到各类应用程序中,助力现有系统的智能化改造,加速推进业务升级。
Jump to section
1. 前言
TRAG:Type-based Retrival-Augmented Generation 基于类型的检索增强生成
大语言模型(以下简称 LLM)本身是一个很好的聊天助手,它可以为我们提供现实中各种场景的对话回复,交互流程是:用户输入问题,LLM 回答输出自然语言。如果是单纯的自然语言,很难作为应用程序的输入。 比如,我们要设计一款智能用户服务,可以通过对话方式来管理用户,我们需要添加一个用户,为了生成接口参数,我们可以通过 Prompt 来引导 LLM,Prompt 如下:
帮忙添加一个名称为 `Jack` 的测试账号,以 JSON 的形式响应
LLM 可能得输出结果如下:
// 结果1
{"name": "Jack", "type": "test"}
// 结果2
{
"username": "Jack",
"type": "test"
}
// 结果3
{
"account": {
"username": "Jack",
"type": "test_user",
}
}
// 结果x
我们可以发现生成的结构可能不太稳定,这就导致我们的程序没法直接使用,为了解决这个问题, OpenAI 推出了 Function Call 的功能,即函数调用。调用 GPT API 时,需要先定义函数,如下:
{
"name": "addUser",
"description": "添加用户",
"parameters": {
"type": "object",
"properties": {
"username": {
"type": "string",
"description": "用户名称"
},
"type": {
"type": "string",
"description": "用户类型",
"enum": ["admin", "test", "normal"]
}
},
"required": ["username"]
}
}
添加函数定义后,GPT API 的返回中,就会携带函数调用相关参数,比如:
id='call_62136354',
function=Function(
arguments='{"username":"Jack","type":"test"}',
name='addUser'),
type='function'
此时我们只需要执行定义好的 addUser 函数就可以了。
Function Call 功能,极大的扩展了 LLM 的应用场景,ChatGPT 官方的应用市场 GPTs 就是基于它实现的。 但是,Function Call 功能同样存在问题,比如:
- 目前只有少数开源大模型支持
- Function Call 目前只支持单个函数调用
- 函数声明不够友好,内部黑盒,强依赖大模型;当返回不符合预期,难以排查
那么如何能够让 LLM 返回,严格遵守我们的应用程序输入呢?
2. TRAG 原理
我们在设计大型软件应用时,往往会选择强类型语言(强类型语言是一种编程语言,其特点是数据类型在使用时必须严格遵守,并且在未经显式转换的情况下,不允许自动将一种数据类型转换为另一种数据类型。),通过一致和严格的类型声明,来约束系统代码,从而提升系统的健壮性和维护性。 同样,我们也可以通过给 Prompt 添加类型声明,来约束 LLM 的返回结果。以下以 TypeScript 语言作为示例。 首先我们声明一个语义类型声明(Schema):
interface SentimentResponse {
sentiment: "negative" | "neutral" | "positive"; // The sentiment of the text
}
然后结合类型声明,定制 Prompt 如下:
You are a service that translates user requests into JSON objects of type "SentimentResponse" according to the following TypeScript definitions:
"""
interface SentimentResponse {
sentiment: "negative" | "neutral" | "positive"; // The sentiment of the text
}
"""
The following is a user request:
"""
It's very rainy outside
"""
The following is the user request translated into a JSON object with 2 spaces of indentation and no properties with the value undefined:
以上提示词,主要含有三个部分:
- 用来指定参考 TypeScript 类型定义
- 用户的请求
- 指定输出 JSON 结构,并且属性值不能是 undefined(未定义)
将拼接后的提示词输入给 LLM 后,它将严格按照类型定义进行返回,如下:
{
"sentiment": "neutral"
}
有时为了验证返回结果有效性,我们还可以通过 zod 进行,可以稍微修改下上面个的类型声明即可:
import { z } from 'zod';
export const SentimentResponse = z.object({
sentiment: z.enum(['negative', 'neutral', 'positive']),
});
export const SentimentSchema = {
SentimentResponse,
};
然后可以针对返回的 JSON 进行验证:
result = {
"sentiment": "neutral"
}
SentimentResponse.safeParse(result)
如果验证不通过,可以再一次将返回 JSON 结果跟之前的 Prompt 进行结合,来让 LLM 进行类型修正,这样就可以做到严格按照应用程序的类型定义进行返回了。
3. TRAG 执行流程
TRAG 的整个执行流程如下:
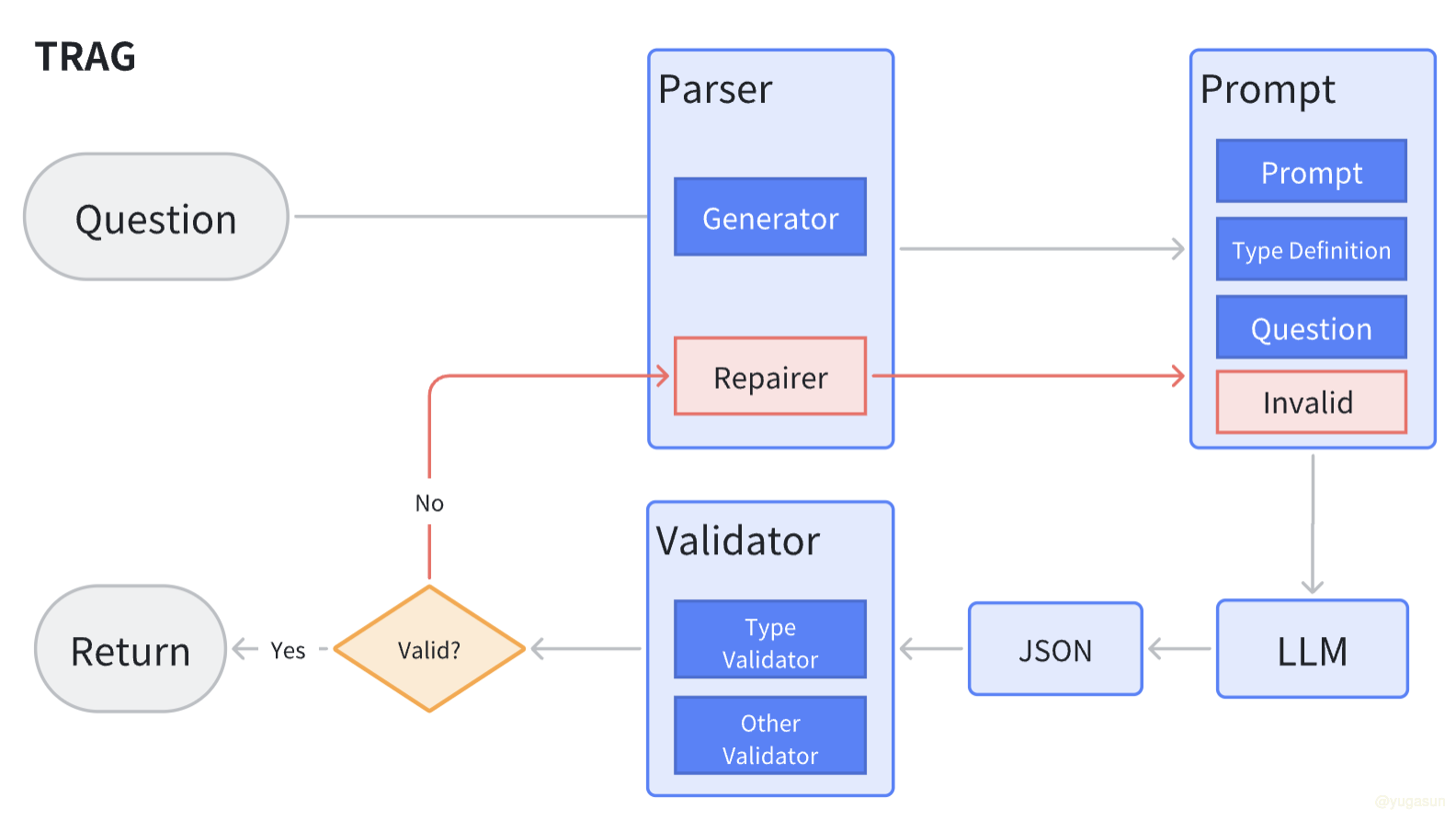
以上流程中,红色部分为输出产物纠错过程。
TRAG 架构包括两个核心模块:
- Parser:主要用来处理提示词,通过将系统提示词、类型定义和用户问题进行组合,输出固定格式的 Prompt
- Validator: 用来进行生成结果的类型检查
如果生成结构未通过类型检查,则会将不符合的结果输入到 Parser 的 Repairer,Repairer 会将之前的系统提示词、类型定义、用户问题和异常 JSON 一起拼接成新的提示词,重新输入给 LLM,进行重试,直到返回正确的结果。
3. TypeChat 简介
基于以上原理,TypeScript 之父 Anders Hejlsberg (同时也是 C#之父!!!) 开源了新项目 TypeChat。 TypeChat 是一个工具库,可以轻松地使用类型构建自然语言界面。使用时,只需定义代表自然语言应用程序中支持的意图的类型即可。这可以像用于对情绪进行分类的界面一样简单,也可以像购物车或音乐应用程序的类型一样复杂。 例如,要向架构添加其他意图,开发人员可以将其他类型添加到可区分联合中。要使架构具有层次结构,开发人员可以使用“元架构”根据用户输入选择一个或多个子架构。 定义类型后,TypeChat 将通过以下方式处理其余部分:
- 使用类型构建 LLM 提示。
- 验证 LLM 响应是否符合架构。如果验证失败,则通过进一步的语言模型交互修复不符合要求的输出。
- 简洁地总结(不使用 LLM)实例并确认它符合用户意图。
比如,对于上面提到的示例,如果使用 TypeChat,代码可以简化为:
import { createJsonTranslator, createLanguageModel, createZodJsonValidator } from '../../src/parser';
import { processRequests } from '../interactive';
import { logger as log } from '../logger';
import { SentimentSchema } from './schema';
async function main() {
// 创建 LLM 实例
const model = createLanguageModel(process.env);
// 定义类型检查器
const validator = createZodJsonValidator(SentimentSchema, 'SentimentResponse');
// 定义 JSON 编译器
const translator = createJsonTranslator(model, validator);
const question = "It's very rainy outside"
// 发送请求
const response = await translator.translate(question);
// 打印结果
console.log(JSON.stringify(response.data))
}
TypeChat 就介绍介绍到这里,感兴趣的朋友可以通过阅读官方源码,进行深入研究。
4. 后记
TRAG 架构是笔者在设计 ChatBI 系统时探索的一种创新实现方案。传统的 RAG 方法在稳定输出用户所需的图表类型方面效果不佳,最终通过 TRAG 架构成功解决了这一问题。未来,笔者还会将 TRAG 应用于通过自然语言操作 RESTful API 服务的场景,从目前的测试结果来看,预期能够顺利实现。 TRAG 架构有效弥合了自然语言与结构化数据之间的鸿沟,使得 LLM 可以更轻松地集成到各类应用程序中,助力现有系统的智能化改造,加速推进业务升级。
Continue your reading
When you finish this article, use these paths to continue the thread.
// tags
Explore adjacent topics and move sideways through the knowledge graph.